Tokens
Think of tokens as the currency AI models use to digest and generate text. Each piece of text is broken down into these units called tokens. The number of tokens can vary based on how common a sequence of characters is and how the AI model has been trained to understand it. It’s like the AI’s vocabulary!
To get a better idea, why not give it a go yourself? Head over to the OpenAI Tokenizer and plug in some text to see how it’s tokenized. It’s pretty cool to see how the AI breaks down your words!
Context
Imagine having a conversation with someone who forgets everything you said a minute ago. Frustrating, right? That’s where context comes into play. The AI keeps track of what has been said previously, storing it in its memory bank to maintain a coherent conversation. This history, or “Context”, isn’t just limited to what you say, though. It also includes instructions, known as system messages, which can be set up when you’re configuring your chatbot or when you’re pulling in dynamic content like a web search. This way, the AI isn’t flying blind—it’s got the backstory!
Messages
Each entry in the context is a message. Think of messages as pieces of a puzzle that the AI puts together to see the full picture. Each message takes up a certain number of tokens, so you’ll want to balance the length and number of messages to avoid overloading the AI, especially since there’s a maximum context size it can handle.
Understanding this in AI Engine
Let’s break down some of the technical jargon and make it easier to understand:
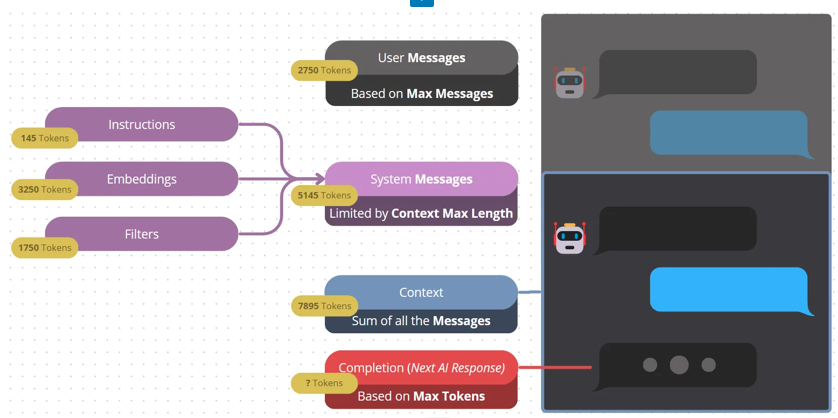
- Max Tokens: This is the limit of how much the AI can process or generate at one time. Different models have different token limits. Most users just want to use the maximum allowed, and honestly, they don’t need to worry about this setting too much. OpenAI needs this value, but we can simplify things for you, look at our recommendations!
- Max Messages: This is all about the conversation history. Think of it like the AI’s short-term memory of what you’ve been discussing. Remember the puzzle pieces we talked about ? You can limit how much of them the AI can play at once with.
- Input Max Length: This one refers to the length of the new message you’re sending to the AI. Keep it concise to stay within limits! This affects the number of charaters allowed in the input box for your chatbot.
- Context Max Length: This isn’t about tokens anymore; it’s the total size of the context if there is one. The context can include previous messages, instructions, embeddings, or other dynamic content.
And a little heads up: it’s now called Context Max Length, not Context Max Tokens, for a bunch of reasons. It’s simpler and faster this way. Plus, calculating tokens on the fly can be tricky and might vary between models and systems, so let’s stick to what’s stable and clear: text length.
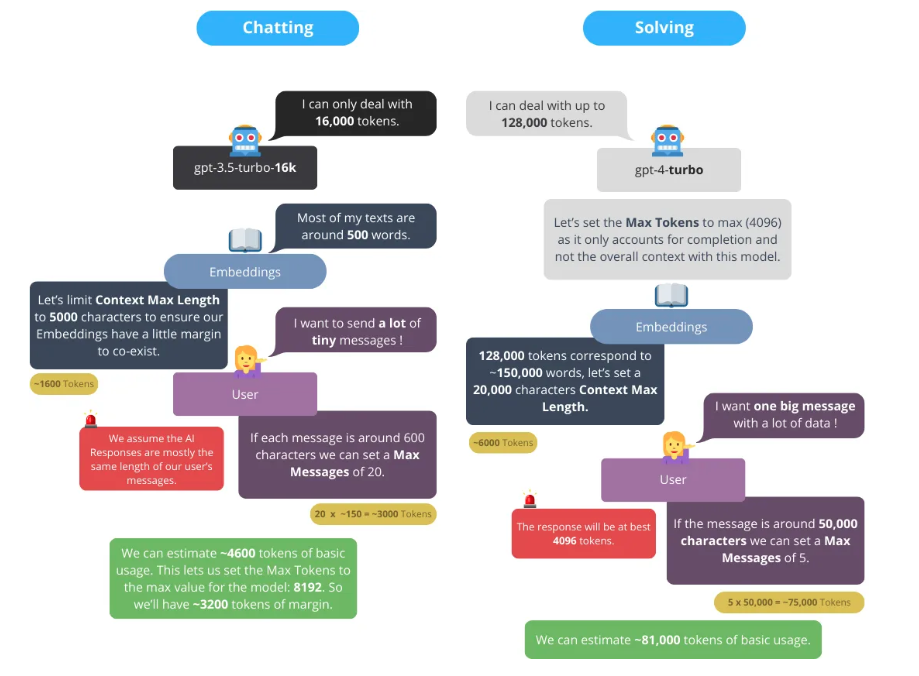
Recommended Values
Modern AI models have very large context windows, so the default values in AI Engine work well for most use cases. As a rule of thumb, 4 characters is roughly equal to 1 token in English. The values below are a good starting point (as of early 2026), but always check the latest model specs from each provider.
Here are some recommended starting values depending on the model you’re using:
OpenAI Models
GPT-4o / GPT-4o mini — GPT-4o supports 128,000 tokens of context and up to 16,384 tokens of output. GPT-4o mini has the same context window at a lower cost. Safe starting values:
Max Tokens: 4096 tokens — Max Messages: 32 messages — Context Max Length: 16384 characters (~4096 tokens)
With 128k tokens of context, you have a lot of room. Feel free to increase Context Max Length or Max Messages based on your needs.
GPT-4.1 / GPT-4.1 mini / GPT-4.1 nano — The newer GPT-4.1 series supports up to 1,000,000 tokens of context, making it excellent for tasks involving very long documents or conversations. The same recommended values apply, and you can increase them significantly.
o3 / o4-mini — These are OpenAI’s reasoning models. They have 200,000 tokens of context and up to 100,000 tokens of output. The same values as GPT-4o work well, but you can increase Max Tokens if you need longer, more detailed responses.
Anthropic Models
Claude (Sonnet, Haiku, Opus) — Claude models support 200,000 tokens of context and up to 8,192 tokens of output (or more with extended thinking). The recommended values are the same as GPT-4o above.
Google Models
Gemini (Pro, Flash) — Gemini models support very large context windows (up to 1 million tokens for some versions). The same recommended values apply, and you can comfortably increase them.
General Tips
For Max Tokens, which is only used for output, it simply means that we don’t limit the AI, and it can use as many tokens as it needs to build its reply. If you want shorter answers, lower it; if you need detailed responses, increase it.
For Max Messages, this controls how much conversation history is kept. More messages means the AI remembers more of the conversation, but also uses more tokens. 32 messages is a good balance for most chatbot use cases.
For Context Max Length, you can increase this significantly with modern models. If you’re using embeddings or long system messages, consider raising it to 32,000 characters or more.