If you’re not interested in knowing how it works and just want to get started, please at least read the Overview section to have a common understanding of what embeddings are.
Even though creating a knowledge base is a complex topic, AI Engine makes it simple. You can just set up your environment, sync your posts, and have your chatbot rely on your site content to generate responses.
In AI Engine, you can build your knowledge base using different services (ranked from easiest to most complex):
Then add your embeddings following this documentation here.
Quick Overview
When a user asks your chatbot a question, the chatbot first converts that question into an embedding. The system then searches your vector database to find the chunks of your documents whose embeddings are most similar (i.e., most relevant) to the question’s embedding. If a match is found, the matching embedding(s) content is added to the context.
This isn’t a keyword search, just having a keyword in your query doesn’t guarantee a match with an embedding.
You cannot ask the chatbot to “search the database” or “search the embeddings”—the chatbot doesn’t know that embeddings exist, nor can it directly access them. You also can’t ask for events happening “this weekend” unless the current date is explicitly provided in the same message. The embeddings match is based on similarity to the vectorized “this weekend” value, not the actual date it corresponds to.
Think of it more like a cloud of points in space, where each point represents a piece of embedded content. When a user submits a query, it’s converted into a vector (by an AI model specifically designed to do this) and placed in that space. The system then looks for the closest points (i.e., most semantically similar content) around that position.
So it’s about conceptual proximity, not exact word matching. Even if a keyword is present, it won’t match unless the meaning of the query is close to the embedded content.
If you are looking for a real search content system, you’ll need to build your own RAG solution using filters and/or function calling. You can learn more about this in the Dynamic Context section.
Learning about Knowledge
How does AI work?
At its core, AI is like a super-smart assistant that learns from data. Modern AI models, such as those based on large language models (LLMs) like GPT, work by processing huge amounts of text and patterns sourced from the internet or custom data. When you ask a question, the AI predicts the best response word by word, based on what it has “learned”.
Context is the “background story” that helps AI understand what you’re really asking. Without it, AI can give vague or incorrect responses. For example, if a customer asks, “How do I return an item?” on your e-commerce site, the AI needs context like your return policy, shipping details, and product specifics to respond helpfully.
In a business setting, context ensures the chatbot doesn’t hallucinate (make up facts) or provide outdated/generic info. By building a knowledge base, you’re giving the AI the right context from your own content, making interactions more personalized and trustworthy.
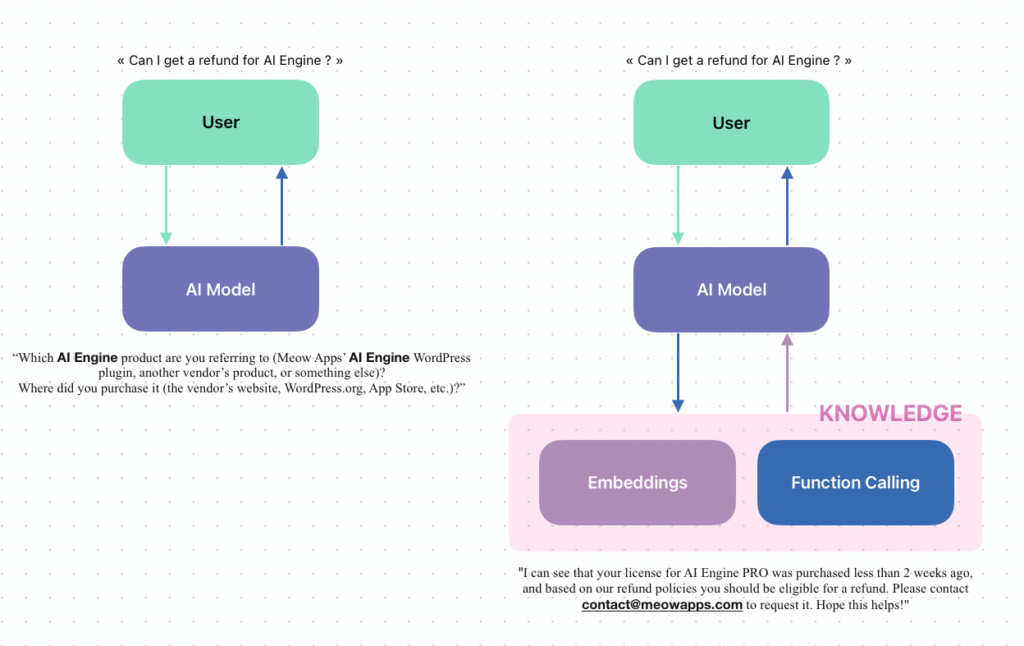
You can see in the example above a regular chatbot with no specific context, and on the right, the usage of embeddings and function calling to create a solid context. Here we’re talking about embeddings, but if you also use function calling you can create behaviors such as letting the AI model call a function to retrieve the purchase, check the license validity, then query the embeddings knowledge base to compare it with the return policy, and finally generate an educated response.
How does the AI use context?
To start, your AI is using instructions as its base guidelines. Technically, you could include all of your information there, what your business does, your contact information, how it should respond, your policies, and more. The AI could then use those instructions to answer.
But AIs have a limited context size, so for a business this isn’t something that could or should be done. For example, if you run an e-commerce site with hundreds or thousands of references, you can’t just input all that data and expect the AI to always pick the right piece of information when needed.
That’s where dynamic content comes into play.
This is exactly like a web search. When you look for information yourself, you don’t open all 1.5 million Wikipedia articles and read through them until you find what you need. Instead, you search for a specific topic related to what you’re looking for, and then you use that article, right? That’s exactly what we’re going to do with your chatbot.
Dynamic Context through RAG
RAG stands for Retrieval-Augmented Generation. It’s a smart way to make AI more accurate by combining two steps:
- Retrieval: The AI searches your knowledge base for relevant information related to the user’s question.
- Generation: It then uses that retrieved info, plus its built-in knowledge, to generate a natural-sounding response.
In simple terms, RAG is like having a librarian (retrieval) who finds the right wikipedia article, and then a storyteller (generation) who summarizes them into an easy-to-understand answer, where the “wikipedia” here would be your own knowledge base, your own corpus of data. This prevents the AI from relying only on its general training, which might not know your business details.
In AI Engine plugin, RAG helps your chatbot pull from your WordPress content or uploaded files to give spot-on replies. You can sync all of your posts, products, PDF files and more to build your knowledge base.
To make RAG work, we don’t rely on an ordinary database like the one used on your WordPress site. Instead, we rely on a specific kind of data storing technology, for which you’ll need to create a dedicated space.
What is a Vector Database and a Vector Store?
A vector database is a special type of database designed to handle “vectors” which are mathematical representations of data like text, images, or sounds. Think of a vector as a list of numbers that captures the essence or meaning of something. For example, the sentence “I love cats” might be turned into a vector like [0.2, 0.5, -0.1, …] based on its semantics.
This vectorization process is not performed by an algorithm or the plugin itself; it is done by AI, by a model that is not designed to generate text but to create these embeddings. The one that will be used in your case is the one set in Settings → AI → Default Environments for AI → Embeddings by default.
The idea here is that with these coordinates we can represent your database content as a cloud of points in space, where all data that share a similar meaning are clustered close to each other. This will be useful later for finding data related to your user’s message, since the message will also be converted into a vector and all the data nearby in the cluster will be fetched as context.
AI Engine will act as the bridge between this vectorized database and the actual textual data of your embeddings.
A vector store is similar, it’s essentially a storage system (often part of a vector database) where these vectors are kept and organized. Think of it as a warehouse for these numerical fingerprints, making it easy to quickly find similar items. This is usually used to store files directly, like PDFs, DOCX, TXT, images, and more, instead of relying only on textual data.
Regular databases (like SQL or NoSQL) are great for structured data, such as customer names, prices, or dates. They store info in tables or key-value pairs and search using exact matches or simple filters. For example, a regular database might find all products priced under $50 by checking numbers directly.
Vector databases, on the other hand, are built for unstructured or semantic data:
- Search Style: They use “similarity search” (e.g., “find things like this”) instead of exact matches. This is perfect for natural language, where meaning matters more than keywords.
- Data Type: They handle high-dimensional vectors (hundreds or thousands of numbers per item), not just text or numbers.
- Speed and Scale: Optimized for quick queries on massive datasets, using techniques like approximate nearest neighbors (ANN) to find close matches without checking everything.
- Use Case: Ideal for AI tasks like recommendations or chatbots, while regular databases are better for transactions or reports.
In short, regular databases are like a phone book (exact lookups), while vector databases are like a search engine (finding related ideas).
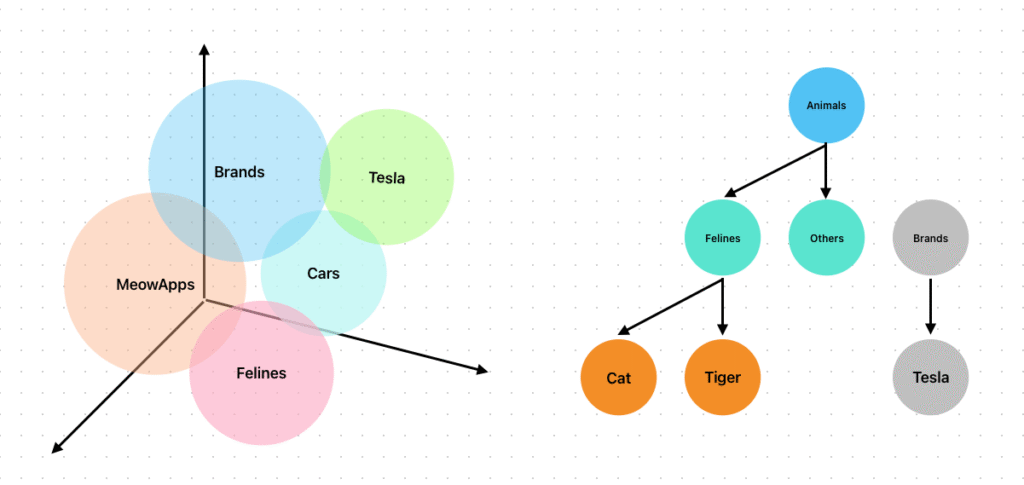
You can imagine how, in a regular database, creating a relation like “Jaguar car brand has a a feline mascot, which is similar to MeowApps’ Nyao cat mascot” would be a real headache to design. In contrast, with vectors in space, all of these topics naturally interconnect with each other.
How Chatbot Uses Vector Databases and Stores
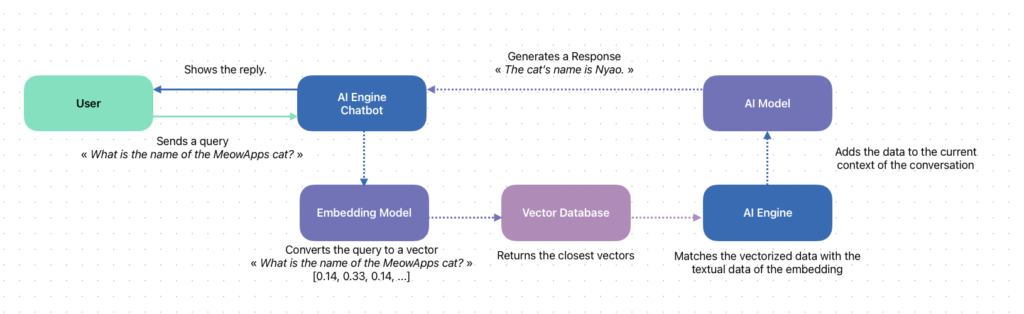
When you build a knowledge base for your AI chatbot:
- Your content (like wordpress posts or PDFs) is broken into small pieces.
- Each piece is converted into a vector using an “embedding” model, which understands meaning.
- These vectors are saved in the vector store/database.
When a user asks a question:
- The question is also turned into a vector.
- The AI searches the vector store for the most similar vectors (using math to measure “closeness” in meaning, not just keywords).
- It retrieves those relevant pieces and uses them in RAG to generate the answer.
This process is fast and efficient, allowing the AI to handle complex queries. For the AI Engine plugin, this means your chatbot can quickly recall info from your site without retraining the entire AI model.